
구름톤에서 시작한 Distance프로젝트는 어느덧 순천향대, 경희대, 동국대, 서울여대, 한국외대를 지나 저희 팀의 리더분 학교인
전남대에도 배포를 하게 되었다.
저희가 이 프로젝트를 구현하고 순천향대에 첫 배포를 할 때 목표가 "서버를 터트릴때까지 해보자!" 였다.
사실 ec2유형이 t2.micro여도 지금까진 단 한번도 서버가 터지지 않고 사용률이 70%이상만 가보기만 했다.
그리고 나름 채팅이 MVP이다보니 I/O가 많을 거 같아 미리 분산을 시켜두면서 나름 준비를 많이 해두었다.
지금 현재 저는 판교에 있는 회사 인턴으로 하고 있는 중 2024/09/12에 전남대 단과대 축제에 맞춰 distance서비스를 배포를 하였다.
오랜만에 배포라서 귀하디귀한(?) 점심시간도 자진 반납을 하고 서버 모니터링을 하였고, 다행히 이상없이 지나가였다..ㅎ
그러고 퇴근 중 갑자기.....리더분에게 다급하게 전화가 왔다..
바로 Slack에 날라오는 에러메시지가 심상치않아서 혹시 확인 한번만 해줄 수 있냐 라고 왔다.
그래서 바로 확인을 해봤는데

위와 같은에러가 뜨면서 서버가 터진거였다..
그래서 바로 그라파나를 통해 서버 상태를 보니까

Heap사용량이 87.9 였고, Load Average에 점처럼 찍혀있고 중간에 빈 부분이 바로 서버가 나간 부분이었다..
한참 그 시간에 사람들의 유입이 많았고, 놓치는 사람들이 많아서 빨리 복구를 해야했다..
저는 아까 그 Slack에 왔던 메시지를 보고 바로 DB가 터진지 알고 DB유형을 t3.micro에서 t3.medium으로 변경을 하고 다시 재배포를 했는데 똑같았다,,,
그렇게 방황하던 중 Heap사용률이 너무 높은게 이상했고, 멘토 분이 ec2를 한번 확인해보라는 말씀을 하셨다.
바로 ec2를 확인해 본 결과

갑자기 ec2사용률이 거의 100을 찍고 사용률이 쭉 내려가는 부분이 있었다.
아마 사용률이 점점 하락하는 부분을 보면 저때 ec2가 부하를 처리하지 못하고 비정상적으로 동작을 하고 뻗었을 것이라고 생각한다.
그래서 왜 갑자기 잘 되던게 뻗었을까 하는 생각을 해보았다.
그러고 디비를 보니 5시30분부터 1시간동안 사용자가 급증하고 채팅이 약 4천개정도 오고 간 것을 확인하였다. (많은 관심 감사합니다ㅎ)
대략 1시간 이상 서버를 복구하지 못하고,, 헤맸고 결과는 해당학교 에타에 일처리 못한다고 올라왔다,,,,
ㅋㅋ사실 이거 보고 긁혔는데 너무 할 말이 없었다,,ㅋ
우선 ec2성능이 너무 작았기 때문에 성능을 t2.xlarge로 높였더니 다행히 정상작동을 하였다.
하지만 뭐가 문제였고, 학생때 트래픽을 경험해보는 좋은 경험을 해보았기 때문에 이번 기회에 제대로 정리를 해보고 싶었다.
우선 QPS를 측정해보자.
QPS란?
QPS(Qureies Per Second)로서 초당 요청 수를 의미함.
이를 통해서 서버가 얼마나 많은 트래픽을 처리할 수 있는지를 파악할 때 주로 사용함.
계산식은 "요청수/초" 를 통해 구할 수 있음.
rate(http_server_requests_seconds_count{job="distanceprod", instance="172.17.0.1:8080"}[1m]) * 60
평균적으로 t2.micro가 수용할 수 있는 QPS는 평균 10~20 정도이다.
Grafana를 통해 distance서버의 QPS를 계산해보면

중간에 그래프가 없는건 서버가 뻗고 다운이 되서 측정이 안된 부분이고, 그 앞 전에 시간을 보면

초당 대략 33개의 요청이 들어왔다는 것을 확인할 수 있고 이는 분당 1980개의 요청이 들어왔다고 할 수 있는 수치이다.
이는 현재 distance에서 사용 중인 t2.micro에선 버티기 어려운 트래픽이었기 때문에 서버가 뻗은 것 같다.
Heap Memory를 분석해보자.
또한 맨 위의 사진을 보게되면 Heap_Used가 87.9%로 굉장히 높은 것을 확인할 수 있다.
이는 OOM(Out Of Memory)이 발생했다는 것을 의미할 수도 있는데 그렇다면 메모리가 부족하다는거고 메모리 누수가 발생하고 있다는 의미일 수도 있다.



위의 사진들을 보면
맨 위의 GC_PAUSE_TIME 패널을 보면 9/12일 15시부터 급격하게 치솟는 파란색 선은 GC중단시간이 급격하게 늘어나고 있는 것을 의미하고 저 그래프를 보면 메모리가 가득차서 GC가 자주 발생하는 것을 볼 수 있다.
GC가 자주 발생했다면 메모리 사용량은 아마 줄어야하는 것이 정상일 것이다.
자 그럼 이제 2번째 사진을 보자.
분명 15시에 GC가 활발하게 동작을 했는데도 불구하고 메모리 사용량이 줄지 않는 것을 확인할 수 있다.
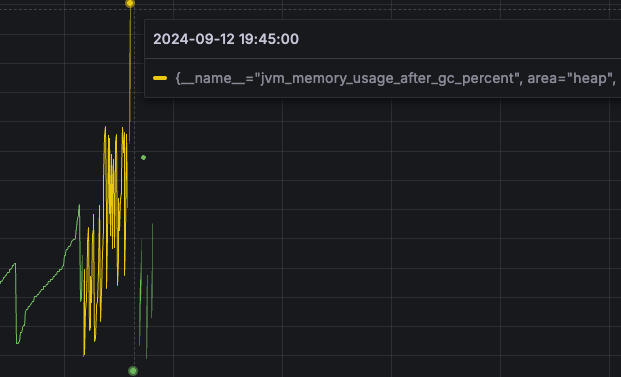
그리고 문제의 Heap사용량을 보자.
3번째 사진을 보면 분명 GC가 동작함에도 불구하고 주황색그래프를 집중해서 보면 Tenured Gen라고 되어 있는데 이 부분은
Old Generation부분이다.
근데 GC가 발생해도 Old Generation의 메모리 사용량이 줄지 않고 늘어나는 것을 확인할 수 있는데 이는 메모리누수가 되고 있다는 증거이기도 하다...
그리고 처음 생각했던 DB의 로그를 확인해봤는데

잠깐 상승한 기록은 있는데 뻗을만큼의 CPU사용률은 없었던 것을 확인할 수 있었습니다.
제가 생각했을 때의 문제는 이번에 회원가입 시 인증번호에 유효시간 기능을 도입하면서 redis를 도입하게 되었는데 redis를 로컬캐시를
사용하도록 해두어서 메모리에 영향을 끼치지않았나 라는 생각이 들었습니다.
그래서 이번 기회에 로컬캐시를 사용하는 부분에서 외부로 분리하는 작업을 해보도록 하겠습니다...!
지금까지 t2.micro유형을 사용하면서 프로젝트를 진행해왔고, 문제가 없어서 잘 사용했는데 이번에 좋은 기회를 통해 트래픽을 경험해보고
성능에 좀 더 신경을 쓰게 되는 좋은 계기가 되었습니다ㅎㅎ
서버의 안정성을 유지하려면 트래픽이 위처럼 급증하는 상황에서 메모리 관리를 얼마나 더 효율적으로 하는지가 중요하다는 것을 깨닫게 되었습니다.
'Project > Distance' 카테고리의 다른 글
| [Distance] API 요청 과부하로부터 서비스를 보호하자. (0) | 2025.03.11 |
|---|---|
| [Distance] - 위치기반 매칭을 INDEX를 통해 개선해보자. (0) | 2025.02.25 |
| [Distance] 짝퉁 카톡(KakaoTalk)을 만들어보자. - SSE (0) | 2024.10.29 |
| [Distance] SQS를 도입해보자. (0) | 2024.10.24 |
| [Trouble Shooting] Refresh Token 구현 (0) | 2024.06.22 |